
Natural Language Processing (NLP) is one of the most exciting branches of artificial intelligence, bridging the gap between human communication and machines. From chatbots to sentiment analysis, NLP is transforming how businesses, researchers, and developers interact with text and speech data. In this blog, we’ll explore 7 essential NLP algorithms and techniques that are crucial for mastering Natural Language Processing.
1. Tokenization
Tokenization is one of the most fundamental steps in Natural Language Processing (NLP). Before any advanced NLP model can understand, analyze, or generate text, it first needs to break down raw text into manageable units called tokens. These tokens can be words, phrases, sentences, or even subwords, depending on the type of tokenization used. This process allows computers to understand the structure of language and perform further operations like sentiment analysis, text classification, machine translation, and more Natural Language Processing.
In essence, tokenization serves as the bridge between human-readable text and machine-readable input. Without this step, NLP models would struggle to interpret raw text efficiently, as computers cannot naturally comprehend the nuances of language. Tokenization provides structure, consistency, and clarity, making it a critical step for any NLP pipeline Natural Language Processing.

Types of Tokenization
Tokenization is not a one-size-fits-all process. There are several methods, each with its own advantages depending on the context:
- Word Tokenization
Word tokenization breaks down sentences into individual words. For example, the sentence:
“Natural Language Processing is amazing.”
becomes:["Natural", "Language", "Processing", "is", "amazing", "."]Word tokenization is simple yet highly effective, particularly for models that analyze meaning at the word level, such as sentiment analysis or keyword extraction Natural Language Processing. - Sentence Tokenization
Sentence tokenization splits a paragraph into sentences. For instance:
“NLP is powerful. It helps machines understand human language.”
becomes:["NLP is powerful.", "It helps machines understand human language."]This method is especially useful for applications like summarization, machine translation, or dialogue systems, where context between sentences matters. - Subword Tokenization
Subword tokenization is a more advanced approach where words are split into smaller units. This method is widely used in transformer-based models like BERT or GPT. For example, the word “unhappiness” might be split into["un", "happiness"]or even smaller subword tokens. Subword tokenization helps NLP models handle rare words, typos, or complex morphological structures efficiently, ensuring better generalization across languages Natural Language Processing.
How Tokenization Works
The process of tokenization may seem simple on the surface, but it requires careful handling of punctuation, whitespace, special characters, and language-specific rules. Here’s a typical workflow:
- Preprocessing
The text is cleaned by removing unnecessary symbols, extra spaces, or special characters. For example, tabs, newlines, or emojis may be standardized or removed Natural Language Processing. - Segmentation
The cleaned text is segmented into units (tokens). Depending on the tokenizer, this could be words, sentences, or subwords Natural Language Processing. - Normalization
Tokens may be further normalized. For instance, converting all tokens to lowercase, stemming words to their root form, or applying lemmatization to reduce words to their canonical form. - Token Mapping
Finally, tokens are mapped to numerical representations, such as indices in a vocabulary or embeddings, so that NLP models can process them Natural Language Processing.
Importance of Tokenization in NLP
Tokenization plays a pivotal role in several NLP tasks. Here are some of its key contributions:
- Improved Text Understanding: By breaking down text into smaller, meaningful units, NLP models can better comprehend context, meaning, and relationships between words.
- Efficiency: Smaller units of text allow models to process information faster and more efficiently. Handling entire paragraphs without tokenization would be computationally expensive.
- Accuracy in Analysis: Tokenization reduces ambiguity. For instance, distinguishing between homonyms, punctuation, or multi-word expressions becomes easier when text is properly tokenized.
- Compatibility with Advanced Models: Most state-of-the-art NLP models, like GPT, BERT, or Transformer-based architectures, rely on tokenized input to perform tasks like text generation, summarization, and translation Natural Language Processing.
Tokenization Challenges
Despite being fundamental, tokenization is not without its challenges:
- Language Diversity
Tokenization rules vary across languages. For example, Chinese or Japanese text does not have spaces between words, making tokenization more complex Natural Language Processing. - Handling Special Characters
Emojis, hashtags, and URLs in social media text can complicate tokenization, requiring specialized preprocessing Natural Language Processing. - Multi-Word Expressions
Some phrases, like “New York” or “machine learning,” should be treated as a single token in certain contexts, which requires advanced tokenization techniques. - Out-of-Vocabulary Words
Rare or new words may not exist in the model’s vocabulary. Subword tokenization helps mitigate this, but it’s still a challenge for NLP systems Natural Language Processing.
Real-World Use Case: Chatbots
One of the most common applications of tokenization is in chatbots and virtual assistants. When a user types a query like:
“Book a flight from New York to London tomorrow.”
The chatbot tokenizes the sentence into units:["Book", "a", "flight", "from", "New York", "to", "London", "tomorrow", "."]
These tokens are then analyzed to understand intent, entities (New York, London, tomorrow), and the action (book a flight). Without tokenization, the chatbot would struggle to process the query and provide an accurate response Natural Language Processing.

Popular Tokenization Tools
- NLTK (Natural Language Toolkit): One of the earliest Python libraries for tokenization and other NLP tasks Natural Language Processing.
- SpaCy: Offers efficient word, sentence, and subword tokenization, optimized for large-scale NLP applications Natural Language Processing.
- Hugging Face Tokenizers: Provides highly efficient tokenizers for transformer-based models, including subword tokenization Natural Language Processing.
2. Part-of-Speech (POS) Tagging
Part-of-Speech (POS) tagging is a crucial step in Natural Language Processing (NLP) that allows machines to understand the grammatical structure of a sentence. In simple terms, POS tagging assigns labels to each word in a sentence, identifying whether it is a noun, verb, adjective, adverb, pronoun, conjunction, or any other grammatical category. This grammatical labeling enables computers to comprehend not just the words themselves, but their roles and relationships within the context of a sentence Natural Language Processing.
Without POS tagging, NLP systems would struggle to understand syntax, meaning, and context, making tasks like machine translation, text summarization, and sentiment analysis far less accurate Natural Language Processing.
How POS Tagging Works
POS tagging generally involves two key steps:
- Tokenization
Before words can be tagged, the text must first be tokenized into individual words or phrases. For example, the sentence v:
“The quick brown fox jumps over the lazy dog.”
is tokenized into:["The", "quick", "brown", "fox", "jumps", "over", "the", "lazy", "dog", "."] - Tagging
Each token is then assigned a grammatical tag based on its role in the sentence. Common tags include:- Noun (NN): person, place, thing (e.g., fox, dog)
- Verb (VB): action or state (e.g., jumps)
- Adjective (JJ): describes a noun (e.g., quick, brown, lazy)
- Adverb (RB): modifies a verb, adjective, or other adverbs
- Preposition (IN): indicates relationships (e.g., over, in, at)
- Determiner (DT): introduces a noun (e.g., the, a, an)
After tagging, the sentence above could be represented as:
[("The", DT), ("quick", JJ), ("brown", JJ), ("fox", NN), ("jumps", VB), ("over", IN), ("the", DT), ("lazy", JJ), ("dog", NN), (".", .)]
This structured representation provides the syntactic framework needed for advanced NLP applications.
Techniques for POS Tagging
POS tagging can be performed using several approaches, ranging from simple rule-based methods to advanced machine learning algorithms:
- Rule-Based Tagging
Rule-based POS taggers rely on manually crafted rules and dictionaries. These systems use patterns in the text, such as “an adjective is usually followed by a noun,” to assign tags. While simple and interpretable, rule-based taggers often struggle with ambiguous words like “book” (which could be a noun or a verb) Natural Language Processing. - Stochastic Tagging
Stochastic, or probabilistic, taggers use statistical models to assign POS tags. A popular method is the Hidden Markov Model (HMM), which calculates the probability of a tag sequence given the observed words. This approach is more flexible than rule-based systems and can handle word ambiguities more effectively Natural Language Processing. - Machine Learning-Based Tagging
Modern POS taggers use machine learning algorithms such as Conditional Random Fields (CRFs) or neural networks. These models learn patterns from large labeled datasets, improving tagging accuracy even for complex or ambiguous sentences Natural Language Processing. - Deep Learning and Transformer Models
The latest NLP models, including BERT, GPT, and other transformer-based architectures, incorporate POS tagging implicitly by learning contextual word representations. These models understand both the grammatical function and semantic meaning of words in a sentence, which significantly enhances downstream NLP tasks Natural Language Processing.
Importance of POS Tagging in NLP
POS tagging is not just an academic exercise; it plays a pivotal role in many real-world NLP applications. Here’s why it is essential:
- Understanding Sentence Structure
POS tagging helps machines comprehend syntactic relationships between words. For example, in the sentence “She saw the man with a telescope,” POS tags help disambiguate whether the telescope belongs to the man or to her. This understanding is crucial for accurate semantic interpretation Natural Language Processing. - Improving Sentiment Analysis
Sentiment analysis tools use POS tagging to distinguish between neutral and opinionated words. For example, adjectives like “fantastic” or “terrible” often indicate sentiment, while nouns or verbs may not. By identifying adjectives, adverbs, and other key parts of speech, sentiment analysis becomes more precise Natural Language Processing. - Enhancing Machine Translation
Translating a sentence from one language to another requires knowledge of grammatical roles. POS tagging provides the syntactic backbone needed for machine translation systems to produce grammatically correct and contextually accurate translations Natural Language Processing. - Facilitating Named Entity Recognition (NER)
POS tags help identify potential entities in text. For instance, proper nouns (NNP) are often candidates for entity recognition, such as names of people, organizations, or locations Natural Language Processing. - Enabling Information Extraction
POS tagging allows NLP systems to extract meaningful relationships from text, such as subject-verb-object triples, which are critical for knowledge graphs, question-answering systems, and summarization.
Challenges in POS Tagging
Despite its importance, POS tagging faces several challenges:
- Ambiguity: Many words have multiple possible tags depending on context. For example, “lead” can be a verb (to guide) or a noun (a metal).
- Complex Sentences: Long or complex sentences with nested clauses increase the difficulty of accurate tagging.
- Low-Resource Languages: POS tagging is more challenging in languages with limited labeled datasets or less rigid grammar.
- Slang and Informal Text: Social media posts, chats, and user-generated content often include slang, typos, and unconventional grammar, making tagging more difficult.
Real-World Use Case: Sentiment Analysis
POS tagging is a critical step in sentiment analysis, particularly for businesses monitoring social media or customer feedback. Consider the review:
“The movie was incredibly exciting, but the ending felt rushed.”
POS tagging identifies the adjectives “exciting” (positive sentiment) and “rushed” (negative sentiment), enabling the sentiment analysis system to generate a balanced and nuanced understanding of the review. Without POS tagging, the system might miss subtle cues and produce inaccurate results.
Popular POS Tagging Tools
- NLTK (Natural Language Toolkit): Offers a robust POS tagger with pre-trained models for English and other languages.
- SpaCy: Known for speed and accuracy, SpaCy provides state-of-the-art POS tagging and syntactic parsing.
- Stanford NLP: A comprehensive NLP library offering POS tagging, dependency parsing, and named entity recognition.
- Hugging Face Transformers: Advanced models like BERT and RoBERTa can perform contextual POS tagging as part of larger NLP pipelines.
3. Named Entity Recognition (NER)
NER identifies and classifies entities in text, such as names of people, organizations, locations, dates, and more. By detecting these entities, NLP models can extract structured information from unstructured text.
Use Case: News aggregators use NER to identify key people, locations, and events mentioned in articles.
4. Sentiment Analysis
Sentiment analysis determines whether a text expresses positive, negative, or neutral feelings. This technique is widely used in social media monitoring, product reviews, and customer feedback analysis.
Use Case: Companies use sentiment analysis to gauge customer satisfaction and brand perception.
5. Word Embeddings
Word embeddings, such as Word2Vec or GloVe, represent words as vectors in a multi-dimensional space. This allows NLP models to understand semantic relationships between words, improving tasks like language translation and question answering.
Use Case: AI-powered search engines use embeddings to return contextually relevant results rather than just exact keyword matches.
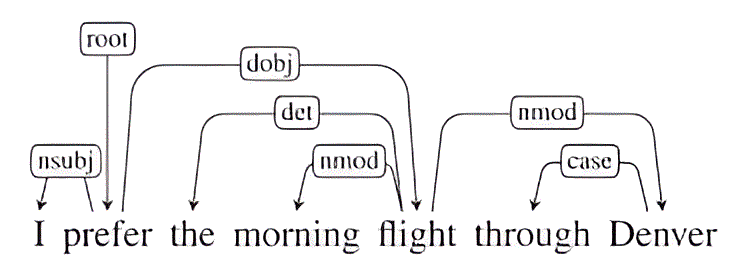
6. Dependency Parsing
Dependency parsing analyzes the grammatical structure of a sentence and identifies relationships between “head” words and dependent words. This is critical for understanding complex sentence structures and extracting meaningful insights from text.
Use Case: Virtual assistants like Siri or Alexa use dependency parsing to comprehend user commands accurately.
7. Text Classification
Text classification is a fundamental technique in Natural Language Processing (NLP) that allows machines to automatically assign predefined categories or labels to text. It transforms unstructured text data—like emails, social media posts, customer reviews, or news articles—into structured, organized information that can be used for a variety of applications. By categorizing text accurately, organizations can gain actionable insights, automate repetitive tasks, and improve decision-making processes.
Whether it’s sorting emails, detecting spam, or labeling content topics, text classification has become an indispensable tool in modern AI-driven applications.
What is Text Classification?
At its core, text classification involves teaching a machine to understand the content of a text and assign it to one or more categories. These categories are usually predefined based on the problem domain.
For example:
- Spam Detection: Emails are classified as “Spam” or “Not Spam.”
- Sentiment Analysis: Customer reviews are categorized as “Positive,” “Neutral,” or “Negative.”
- Topic Labeling: News articles are assigned to topics like “Politics,” “Technology,” or “Sports.”
Text classification transforms raw text into structured data that is easier to analyze, interpret, and act upon.
How Text Classification Works
Text classification typically involves several key steps:
- Text Preprocessing
Before classification, text needs to be cleaned and standardized. Preprocessing includes:- Removing punctuation, special characters, and stopwords
- Lowercasing all text for uniformity
- Tokenization (splitting text into words or subwords)
- Lemmatization or stemming to reduce words to their root form
- Feature Extraction
Once the text is cleaned, it must be converted into a numerical representation so a machine learning model can process it. Common feature extraction methods include:- Bag of Words (BoW): Represents text as a vector of word frequencies.
- TF-IDF (Term Frequency-Inverse Document Frequency): Weighs words based on how important they are across the dataset.
- Word Embeddings: Advanced methods like Word2Vec, GloVe, or transformer-based embeddings convert words into dense vectors capturing semantic meaning.
- Model Training
After feature extraction, the machine learning or deep learning model is trained on labeled text data. Common algorithms include:- Naive Bayes: A probabilistic model ideal for spam detection and text categorization.
- Support Vector Machines (SVM): Effective for high-dimensional feature spaces.
- Random Forests and Decision Trees: For smaller datasets and interpretable models.
- Deep Learning Models: LSTM, CNN, and transformer-based architectures like BERT have revolutionized text classification by understanding context and semantics.
- Prediction and Evaluation
Once trained, the model can predict categories for new, unseen text. Performance is evaluated using metrics like accuracy, precision, recall, F1-score, and confusion matrices, ensuring that the model reliably categorizes text across different classes.
Types of Text Classification
Text classification can be broadly categorized into several types:
- Binary Classification
Involves classifying text into two categories, such as spam vs. not spam, positive vs. negative sentiment, or fraudulent vs. legitimate transactions. - Multi-Class Classification
Involves classifying text into more than two categories, such as labeling news articles into sports, politics, or technology. - Multi-Label Classification
Each piece of text can belong to multiple categories simultaneously. For instance, a blog post might be labeled as both “AI” and “Finance” if it discusses AI applications in banking.
Importance of Text Classification in NLP
Text classification is critical for many NLP applications due to its ability to organize and interpret massive volumes of text data efficiently. Some of the key benefits include:
- Automation of Repetitive Tasks
Tasks like email filtering, ticket routing, and document labeling can be automated, saving time and reducing human error. - Enhanced Decision-Making
By categorizing and analyzing text data, organizations can make data-driven decisions, such as understanding customer feedback or identifying emerging trends. - Improved Customer Experience
Classifying support tickets or chat queries enables businesses to route requests faster, ensuring timely responses and higher customer satisfaction. - Content Organization
Websites, news portals, and content platforms use text classification to categorize articles, blogs, and posts, making content discovery easier for users.
Challenges in Text Classification
Despite its benefits, text classification comes with its own set of challenges:
- Ambiguity in Language: Words with multiple meanings (polysemy) can confuse models if context is not properly understood. For example, “bank” could mean a financial institution or the side of a river.
- Imbalanced Datasets: Some categories may have significantly fewer examples than others, causing models to be biased toward the more frequent classes.
- Noise in Data: Social media texts, informal language, emojis, and typos can affect classification accuracy.
- High Dimensionality: Text data often contains thousands of unique words, making computation complex without proper feature extraction techniques.
Advanced models like transformers and contextual embeddings have helped overcome many of these challenges by understanding word meaning based on context rather than relying solely on individual word frequencies.
Real-World Use Case: Email Filtering
One of the most common applications of text classification is in email filtering. Email services like Gmail automatically categorize incoming emails into Primary, Social, Promotions, and Spam.
Here’s how it works:
- Incoming emails are preprocessed and tokenized.
- Features like word frequency, subject line keywords, and sender patterns are extracted.
- A trained classifier predicts the appropriate category for each email.
This process not only keeps inboxes organized but also protects users from spam, phishing attacks, and unwanted content, demonstrating how text classification improves productivity and security.

Popular Tools and Libraries for Text Classification
- Scikit-learn: Offers a wide range of traditional machine learning algorithms for text classification.
- NLTK (Natural Language Toolkit): Provides preprocessing, tokenization, and feature extraction tools.
- SpaCy: Supports text classification pipelines and integration with deep learning frameworks.
- Hugging Face Transformers: Provides state-of-the-art models like BERT, RoBERTa, and DistilBERT for highly accurate contextual text classification.
- TensorFlow and PyTorch: Popular deep learning frameworks for building custom text classification models more to know click here…https://sunscrapers.com/blog/9-best-python-natural-language-processing-n
🔹 Conclusion
Mastering these 7 essential NLP algorithms and techniques is key to unlocking the potential of Natural Language Processing. Whether you’re building chatbots, analyzing social media data, or developing AI-powered search engines, understanding these methods will give you a competitive edge in the field of AI and data science.
NLP is continuously evolving, and new techniques like transformer models and large language models (LLMs) are taking this field to unprecedented heights. By combining these algorithms and techniques, you can develop smarter, more efficient, and human-like AI systems http://decodeai.blog.