
Introduction
There was a time when machines could only follow instructions that humans explicitly programmed into them: “Do X, then Y, then Z.” But today, thanks to rapid advances in computer vision, machines are beginning to see, understand, and interpret the world around them — much like humans do. One of the most exciting capabilities within this field is object detection, the technology that enables computers to identify and locate objects in images and video with remarkable accuracy Computer Vision .
Computer vision and object detection aren’t futuristic concepts anymore. They are woven into technologies we interact with every day — from unlocking phones with facial recognition to advanced sensors in autonomous cars that detect pedestrians and street signs. Yet, most people still don’t fully grasp what these technologies are, how they work, or why they are so transformative Computer Vision .
This blog dives deep into the world of computer vision and object detection — explaining them in simple terms, exploring how they work, surveying real‑world applications, and looking at future possibilities.

1. What Is Computer Vision?
At its core, computer vision is a field of artificial intelligence (AI) that enables computers to interpret and make decisions based on visual data — including images and videos. Think of it as teaching machines to see like humans do.
Unlike traditional programming, where rules are explicitly coded, computer vision systems learn from data. They analyze thousands (or even millions) of images to recognize patterns. The more data they see, the better they become at making sense of visual input….https://www.ibm.com/think/topics/computer-vision
1.1. Why Computer Vision Matters Today
Computer vision is important because the world is visual. Humans rely on sight for almost everything — and now machines are catching up. Vision gives AI systems context, allowing them to:
- Identify objects and people
- Track motion and changes over time
- Understand complex scenes
- Act in the physical world based on what they see
Without vision, many autonomous systems would be blind. Vision is the bridge between raw pixels and meaningful decisions.
2. A Closer Look at Object Detection
Object detection is one of the most powerful and widely used tasks in computer vision. Unlike simpler image analysis techniques, object detection allows machines to both recognize what objects are present in an image and determine exactly where those objects are located. This dual capability makes it a cornerstone of many real-world AI applications, from autonomous vehicles to smart security systems.
At a basic level, object detection answers two essential questions at the same time:
What is in the image? and Where is it?
This makes it far more informative and practical than image classification alone.

How Object Detection Differs from Image Classification
To understand why object detection is so powerful, it helps to compare it with image classification. Image classification focuses only on identifying the main object or category within an image. For example, a classification model might analyze a photo and say, “This image contains a cat.”
Object detection goes a step further. It not only recognizes that a cat is present but also draws a box around the cat, showing its precise location. If there are multiple cats—or different objects like dogs, people, or vehicles—the model can detect and label each one individually.
This ability to identify multiple objects and their positions is what enables practical applications in dynamic, real-world environments.
Core Components of Object Detection
In technical terms, object detection relies on three key components that work together to deliver accurate results:
1. Bounding Boxes
Bounding boxes are rectangular outlines drawn around detected objects. They define the spatial location of each object within the image. These boxes allow systems to understand where an object begins and ends, which is crucial for tasks like tracking movement or avoiding obstacles.
2. Labels
Each bounding box is assigned a label that identifies the type of object detected, such as “car,” “person,” “dog,” or “traffic light.” Labels give semantic meaning to the visual data, allowing machines to interpret the environment in a human-like way.
3. Confidence Scores
Confidence scores indicate how certain the model is about each detection. These scores help systems decide whether a detection should be trusted or ignored. For example, a detection with a 95% confidence score is far more reliable than one with a 40% score.
Together, bounding boxes, labels, and confidence scores create a structured and interpretable output that machines can use for decision-making.
How Object Detection Models Work
Object detection models are typically built using deep learning, especially convolutional neural networks (CNNs). These models are trained on large datasets containing images with annotated bounding boxes and labels. Through training, the model learns patterns such as shapes, textures, edges, and spatial relationships.
Modern object detection architectures analyze an image in a single pass or multiple stages, predicting object locations and classes simultaneously. This efficiency allows object detection to be used in real-time systems where speed and accuracy are critical.
Why Object Detection Is More Advanced
Object detection is considered more advanced than simple classification because it requires a deeper understanding of visual scenes. The model must identify multiple objects, distinguish between overlapping elements, and handle variations in lighting, angle, size, and background.
For example, detecting pedestrians in a crowded street scene is significantly more complex than classifying a single image as “street” or “city.” Object detection must accurately locate each person, even when they partially overlap or appear at different distances.
Real-World Applications of Object Detection
The practical value of object detection lies in its wide range of real-world applications:
Surveillance and Security
Object detection is used to identify people, vehicles, and unusual activity in surveillance footage. It helps automate monitoring, reduce false alarms, and enhance public safety.
Autonomous Vehicles
Self-driving cars rely heavily on object detection to recognize pedestrians, traffic signs, vehicles, and obstacles. Accurate detection ensures safer navigation and real-time decision-making.
Smart Home Devices
Smart cameras and home automation systems use object detection to identify people, pets, and deliveries. This enables personalized alerts and improved security.
Healthcare
In medical imaging, object detection helps identify tumors, fractures, or abnormalities in scans, assisting doctors with faster and more accurate diagnoses.
Retail and E-commerce
Retailers use object detection for inventory management, customer behavior analysis, and automated checkout systems.
Challenges in Object Detection
Despite its power, object detection is not without challenges. Models must handle occlusion, small objects, cluttered backgrounds, and varying image quality. Achieving high accuracy while maintaining real-time performance can be technically demanding.
Additionally, training effective object detection models requires large, well-labeled datasets, which can be time-consuming and expensive to create.
The Future of Object Detection
As computing power and AI research continue to advance, object detection models are becoming faster, more accurate, and more efficient. Emerging techniques focus on reducing computational costs while improving detection in complex environments.
These improvements will further expand the role of object detection in everyday technologies, making AI systems more aware, responsive, and intelligent.
Conclusion
Object detection is a fundamental and transformative task within computer vision. By answering both what objects are present and where they are located, it enables machines to understand and interact with the visual world in meaningful ways.
Through bounding boxes, labels, and confidence scores, object detection provides structured insights that power applications ranging from surveillance and smart homes to autonomous vehicles and healthcare. As the technology continues to evolve, object detection will remain a key building block of intelligent, real-world AI systems.
3. How Object Detection Works
Object detection relies on deep learning, especially convolutional neural networks (CNNs). While the mathematics behind it can be complex, the fundamental idea is straightforward: the system learns from countless examples so it can generalize to new images.
3.1. Training Phase
During training:
- The model learns to recognize patterns from labeled images.
- Each image contains objects annotated with bounding boxes and labels.
- The network adjusts itself to reduce errors over time.
By exposing the AI to many variations — different angles, lighting conditions, and object sizes — it becomes more robust.
3.2. Inference Phase
Once trained, the model can detect objects in new, unseen images. It scans the image and predicts:
- What objects are present
- Where they are located
- How confident it is about each prediction
This process must be both accurate and efficient, especially for real‑time applications like video analysis or autonomous driving.
4. Popular Object Detection Models
Over the years, researchers have developed many object detection algorithms. Some of the most well‑known include:
4.1. R‑CNN Family
- R‑CNN — One of the first deep learning‑based detectors
- Fast R‑CNN & Faster R‑CNN — Improved speed and accuracy over time
4.2. YOLO (You Only Look Once)
- Designed for real‑time detection
- Splits images into grid cells and predicts objects in each
- Extremely fast and widely used
4.3. SSD (Single Shot MultiBox Detector)
- Another real‑time model
- Performs detection in a single pass
Each model has trade‑offs between speed, accuracy, and computational requirements. The best choice depends on the application.
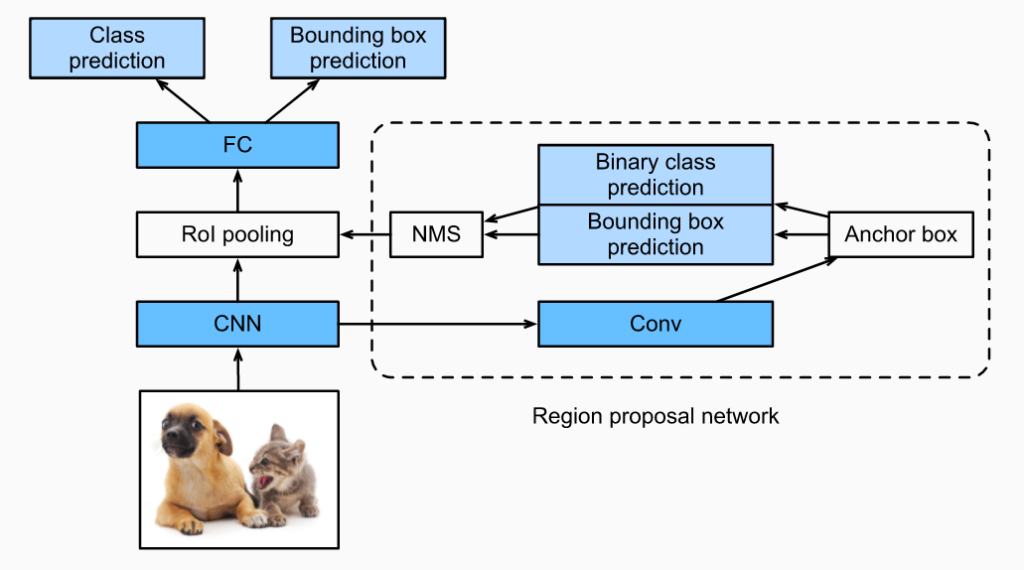
5. Real‑World Applications of Computer Vision and Object Detection
Once you understand what object detection is and how it works, it’s easy to appreciate how pervasive it’s become.
5.1. Autonomous Vehicles
Self‑driving cars rely on computer vision to:
- Detect pedestrians, cyclists, and vehicles
- Recognize traffic signs and lights
- Understand road conditions
Here, object detection isn’t just convenient — it’s a matter of safety.
5.2. Health Care
In medical imaging, computer vision helps in:
- Detecting tumors in scans
- Highlighting anomalies in X‑rays or MRIs
- Assisting radiologists with early diagnosis
The ability to spot patterns humans might miss can significantly improve outcomes.
5.3. Retail and Inventory
In retail environments, object detection powers:
- Automated checkout systems
- Inventory tracking with smart cameras
- Theft prevention systems
This reduces manual labor and speeds up operations.
5.4. Security and Surveillance
Smart cameras can identify unusual behavior — like unattended bags or people entering restricted zones — and alert authorities, providing a more proactive form of security.
5.5. Augmented Reality (AR)
Apps that overlay digital information on real‑world views depend on object detection to:
- Recognize objects in the environment
- Overlay graphics in contextually meaningful ways
Games, education apps, and virtual shopping experiences all benefit.
6. Challenges in Object Detection and Computer Vision
Object detection and computer vision have made remarkable progress in recent years, powering applications such as facial recognition, autonomous vehicles, medical imaging, and smart surveillance systems. However, despite these advances, computer vision models still face several fundamental challenges when operating in real-world environments. Unlike controlled datasets, real-world images and videos are unpredictable, noisy, and complex.
Understanding these challenges is essential for researchers, developers, and organizations aiming to build reliable vision-based AI systems.
6.1 Occlusion: When Objects Are Partially Hidden
Occlusion occurs when an object is partially or fully blocked by another object in the scene. For example, a pedestrian may be partially hidden behind a vehicle, or a product on a shelf may be obscured by another item. In such cases, object detection models may struggle to recognize or correctly classify the object.
From a technical perspective, occlusion disrupts the visual patterns that models rely on to make predictions. When key features such as edges or shapes are missing, the model may fail to detect the object or confuse it with something else.
Occlusion is particularly challenging in crowded environments, such as city streets, shopping malls, or sports events. Researchers address this issue by using larger and more diverse training datasets, multi-view imaging, and advanced architectures that learn contextual relationships between objects.
6.2 Lighting Variations: The Impact of Illumination
Lighting conditions play a critical role in how objects appear in images. Changes in illumination, such as shadows, glare, reflections, or low-light environments, can significantly affect detection accuracy. An object captured in bright daylight may look very different at night or under artificial lighting.
For example, glare from sunlight can wash out important features, while shadows can distort object shapes. Low-light conditions introduce noise, making it harder for models to distinguish between objects and the background.
This challenge is common in applications like surveillance, autonomous driving, and outdoor robotics. To combat lighting variations, researchers use data augmentation techniques, image normalization, and sensor fusion methods that combine visual data with infrared or depth information.
6.3 Scale Differences: Objects of Varying Sizes
Scale variation refers to objects appearing at different sizes depending on their distance from the camera. A car close to the camera may occupy a large portion of the image, while another car far away may appear as a small cluster of pixels.
Detecting small objects is especially difficult because they contain fewer visual details. Small-scale objects are more likely to be missed or misclassified, particularly in high-resolution scenes with many elements.
This challenge is critical in applications such as drone surveillance, satellite imagery, and traffic monitoring. Researchers address scale differences by using multi-scale feature extraction, image pyramids, and specialized neural network layers that capture information at different resolutions.
6.4 Real-World Noise: Imperfections in Visual Data
Real-world images are rarely clean or perfect. Motion blur, camera shake, compression artifacts, background clutter, and visual distortions introduce noise that can confuse computer vision models. For instance, a fast-moving object may appear blurred, making it harder to detect accurately.
Background clutter is another major issue. In complex environments, objects may blend into the background, reducing contrast and making detection more difficult. This is especially problematic in outdoor scenes with varied textures and colors.
To handle real-world noise, researchers train models on diverse datasets that include imperfections. Techniques such as noise reduction, temporal analysis in videos, and attention mechanisms help models focus on relevant visual information.
The Challenge of Generalization
One of the biggest challenges in computer vision is generalization—the ability of a model to perform well on unseen data. A model trained in one environment may struggle when deployed in a different setting with new lighting, backgrounds, or object appearances.
This issue highlights the importance of robust training strategies and continuous model evaluation. Domain adaptation and transfer learning are commonly used to improve generalization across different environments.
Computational and Hardware Constraints
Advanced object detection models often require significant computational resources. Running these models in real time on edge devices, such as smartphones or IoT cameras, introduces additional challenges. Balancing accuracy, speed, and energy efficiency is a constant concern.
Researchers are developing lightweight models and optimization techniques to make computer vision more accessible and practical for real-world deployment.
Ongoing Research and Innovation
Despite these challenges, the field of computer vision continues to evolve rapidly. Researchers are exploring new architectures, training strategies, and multimodal approaches that combine vision with audio, text, or sensor data.
Innovations such as self-supervised learning, transformer-based vision models, and improved data augmentation methods are helping reduce the impact of occlusion, lighting variations, scale differences, and noise.
Conclusion
While object detection and computer vision have achieved impressive milestones, real-world challenges remain a significant hurdle. Occlusion, lighting variations, scale differences, and real-world noise continue to test the limits of current models.
However, continuous research and technological innovation are steadily improving robustness and reliability. As these challenges are addressed, computer vision systems will become more accurate, adaptable, and capable of operating effectively in complex, real-world environments.
7. Tools and Frameworks for Building Vision Systems
For developers, there are powerful tools and libraries that make building object detection systems accessible:
- TensorFlow & TensorFlow Lite
- PyTorch
- OpenCV
- Detectron2
- Darknet (for YOLO)
These tools provide pre‑built models and APIs that simplify training, evaluation, and deployment — even for beginners.
8. Object Detection in 2025 and Beyond
The future of object detection within computer vision is bright:
8.1. Edge AI
Models are now being designed to run on edge devices — like phones, cameras, and sensors — without needing cloud processing. This improves speed, privacy, and reliability.
8.2. Multimodal Understanding
Next‑gen systems won’t just detect objects; they will understand context. For example, recognizing that a person holding an umbrella exists because it’s raining — merging vision with weather data.
8.3. 3D Vision
Depth perception will become more advanced, allowing machines to understand the world in three dimensions, not just flat images.
8.4. Collaborative AI
AI systems will work with humans more seamlessly — proactively assisting in decision‑making rather than just reporting what they see.
9. FAQs — Common Questions About Computer Vision and Object Detection
Q1. Is object detection the same as image classification?
No. Image classification just labels what’s in the image. Object detection locates and labels objects.
Q2. How accurate is object detection today?
Modern models can achieve over 90% accuracy on standard benchmark datasets — and performance keeps improving.
Q3. Can object detection work in real time?
Yes! Models like YOLO and SSD are designed for real‑time detection on video feeds.
Q4. Do I need coding skills to work with computer vision?
Basic coding helps, especially in Python, but many tools now offer drag‑and‑drop interfaces and pre‑trained models.
10. Conclusion
Computer vision and object detection are revolutionizing how machines interact with the world. What was once science fiction is now embedded in everyday life — from smart cameras to driverless cars.
As the technology evolves, its applications will expand into new domains, helping save lives, streamline industries, and create more intuitive ways for humans and machines to collaborate.
Whether you are a student curious about AI, a developer building the next breakthrough app, or a business owner exploring innovation, computer vision and object detection offer exciting opportunities….Blogs